谁知道这里面有多少小技巧,没准哪个能帮上你呢?(•̀⌄•́)
—— by JiHan
ssh免密登录
A是主机,B是远程服务器
原理:
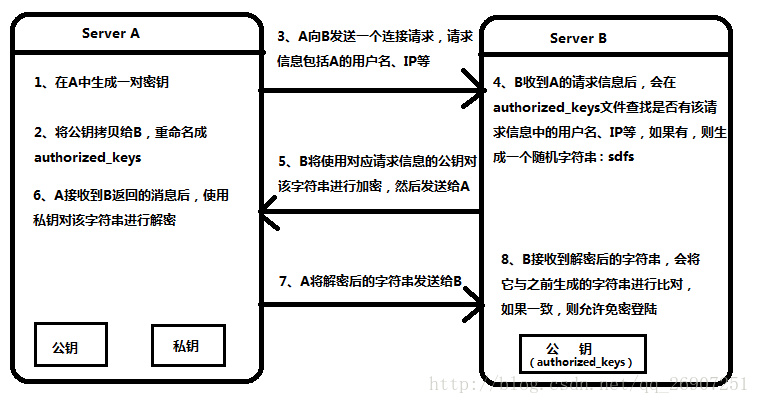
实际配置:
-
生成秘钥对:
本地主机:1
ssh-keygen -t rsa
-
拷贝公钥到远程主机:
-
简单方法,在本地主机执行:
1
ssh-copy-id remote_username@server_ip_address -p port
不加
-p默认22端口
然后输入密码即可 -
先登录远程主机:
-
获取本地主机的公钥,追加到
authorized_keys:1
cat id_rsa.pub >> authorized_keys
-
修改权限:
1
chmod 600 authorized_keys
-
重启服务(不一定需要):
1
service sshd restart
-
-
-
配置ssh名称(可选)
为了方便记住输入远程主机设备,可给远程主机配置名称。1
2
3
4
5
6# vi ~/.ssh/config
Host remote
User root
Hostname 192.168.0.1
Port 22
# ssh remote
测试:
本地主机登录远程主机:
1 | ssh remote@<ip> |
配置ssh禁用密码登录:
增加安全性,避免别人尝试非法登录。
-
完成上述的免密登录,服务端获得一个公钥,本机获得一个私钥
-
将私钥保存,供其他设备使用
-
设置服务端配置文件
/etc/ssh/sshd_config,关闭密码登录:1
2
3
4
5#禁用密码验证
PasswordAuthentication no
#启用密钥验证,下面两个默认都是开启的
RSAAuthentication yes
PubkeyAuthentication yes -
重启sshd服务:
1
systemctl restart sshd
VSCODE(配置同步到github账号:gotables)
插件列表:
- Remote-SSH:远程ssh登录,linux版本太低不支持
- sftp:远程文件同步
- vscode-icons:文件图标显示
- markdown all in one:Markdown插件
- markdown preview Enhanced:Markdown预览
cmd:Markdown Preview Enhanced: Customize Css
background-color: rgb(157, 189, 189);
font-family: -apple-system, BlinkMacSystemFont, “Segoe UI”, Helvetica, Arial, sans-serif, “Apple Color Emoji”, “Segoe UI Emoji”, “Segoe UI Symbol”, “微软雅黑”; - tabNine:机器学习补全(可能导致和语言补全冲突)
- go 补全插件,建议使用gopl,之前补全太慢,解决
- koroFileHeader:用于生成标准格式函数头说明,或者代码文件头说明
- bookmarks:给代码打标签
- Draw.io integration:drawio的绘图插件
- 格式补全:在命令行输入:Format Document 或 Format Selection
- koroFileHeader插件对应命令:fileheader或cursorTip(函数头注释),各种语言都支持
- Doxygen Documentation Generator插件也用于生成注释,只需要输入/**回车就行,文件注释和函数注释都是(貌似只针对c/cpp)
- 针对golang的注释插入:安装Go extension for Visual Studio Code,然后在代码中使用/**或者///来开始一个注释块,并按回车键。
C 段错误处理(Linux)
- 必须先得到段错误的地址,可以用gdb的bt或者在程序中捕捉段错误堆栈。
SIGSEGV, SIGABRT - 在可以编译的机器上源码编译,带上行号和函数名,使用
addr2line -f -e <file> <addr>来映射到具体的函数位置。 objdump -D <file> | grep -A 50 -B 50 <addr>也能查到对应汇编代码,从而定位函数。
进程运行状态查看
pstack <pid> 查看当前运行程序的运行状态,非常方便排查阻塞和死锁问题。
ps aux --sort -rss 按照内存占用排序,排查进程内存泄漏。
ps v <pid>查看某个进程具体的信息,类似top列出的进程信息。
断言assert
处理程序中不应该发生的错误,常用在参数检查。
参考1, 参考2
ipset源码技巧
ipset源码分析
-
这里有个很牛皮的操作,在c里面实现的模块化加载。具体操作如下:
如果我想在ipset中支持一种新的添加规则,比如hash:ip,那么,我需要改多少源码?1
2
31. 按照格式写好ipset_hash_ip.c里面包含了hash:ip的传输规则和初始化方法。
2. 重新执行configure,加入这个规则(这里具体实现我没有确认,但猜测如此)
3. 执行make那么其具体实现方法如何?
1
2
31. 首先在configure中会根据你配置的支持规则模块生成makefile,makefile中就会包含编译这个模块的源文件。
2. make时会根据配置产生的源文件列表,生成一个type_init.c文件,里面包含了所有规则模块的初始化。
3. 主函数会调用type_init.c源文件,将初始化好的规则加载到一个全局链表中,在规则匹配的时候进行匹配。这种方法就实现了模块化的添加和删除规则模块的方法。这种模块化的思想,在其他语言里并不少见,但是在c语言里面实现的,还是少见(菜鸡的我反正第一次见)
-
提供了接口,自定义输出函数和日志输出文件。
-
X Macros宏使用,类似定义一个map,但是比map功能更丰富。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// Defines four variables.
X(value1, 1) \
X(value2, 2) \
X(value3, 3) \
X(value4, 4)
// driver program.
int main(void)
{
// Declaration of every variable
// is done through macro.
VARIABLES
// String values are accepted
// for all variables.
VARIABLES
// Values are printed.
VARIABLES
return 0;
}实际上预编译后的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
int main(void)
{
char value1[10];
char value2[10];
char value3[10];
char value4[10];
scanf("\n%s", value1);
scanf("\n%s", value2);
scanf("\n%s", value3);
scanf("\n%s", value4);
printf("%d) %s\n", 1, value1);
printf("%d) %s\n", 2, value2);
printf("%d) %s\n", 3, value3);
printf("%d) %s\n", 4, value4);
return 0;
}示例2:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
// Defining a macro
// with the values of colors.
X(RED) \
X(BLACK) \
X(WHITE) \
X(BLUE)
// Creating an enum of colors
// by macro expansion.
enum colors {
COLORS
};
// A utility that takes the enum value
// and returns corresponding string value
char* toString(enum colors value)
{
switch (value) {
case color: \
return #color;
COLORS
}
}
// driver program.
int main(void)
{
enum colors color = WHITE;
printf("%s", toString(color));
return 0;
}实际上预编译后的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
// Creating an enum of colors.
enum colors {
RED,
BLACK,
WHITE,
BLUE
};
/*A utility that takes the enum value and returns
corresponding string value*/
char* toString(enum colors value)
{
switch (value) {
case RED:
return "RED";
case BLACK:
return "BLACK";
case WHITE:
return "WHITE";
case BLUE:
return "BLUE";
}
}
// driver program.
int main(void)
{
enum colors color = WHITE;
printf("%s", toString(color));
return 0;
}X macros 主要适用于多中类型有相同的处理逻辑。简单的类似enum中int到string的映射,复杂的到ipset的多种类型处理。
-
gcc 编译debug模式或者自定义模式。
-Dxxx。示例:
test.c:1
2
3
4
5
6
7
8
9#include <stdio.h>
int main(int agv, char *agrs[]){
#ifdef TEST
printf("ENABLE TEST\n");
#endif
printf("test over\n");
return 0;
}执行TEST:
1
2
3
4
5
6
7$ gcc test.c -DTEST -o test
$ ./test
ENABLE TEST
test over
$ gcc test.c -o test
$ ./test
test over这种方式在做C的模块编译,以及Debug编译特别有效。DEBUG适合开源代码,不适合现场代码排查。
15个最常用的GCC编译器参数 -
源码编译的时候,缺少依赖库。
- 一般的解决方法,都是直接用yum install libxxx-devel.x86_64,再次进行configure。
- 如果还不成功,就检查你的
PKG_CONFIG_PATH变量是否存在,不存在添加对应的环境变量(默认一般在/usr/lib64/pkgconfig/)。 - 如果还不行,就执行
/usr/bin/pkg-config --exists --print-errors "libxxx >= x.x.xx"(通常这个命令可以在configure文件中找到),然后再根据问题来排查。 - 最后的方法,就是用
./configure --help来找到对应的库的环境变量名称,修改对应的libxxx_LIBS
一些工具
go好用的开源组件
配置文件读写:
日志:
web服务:
go编写命令:
restful 文档生成:
Go技巧
- 测试
xrags
常见的用法:
ls | xargs echo相当于echo a b cls | xargs -i echo {}相当于echo a; echo b; echo c,-i同-I '{}',其含义是将{}内的内容替换成前面输出的内容,并且循环执行。-t参数可以查看你xargs执行的命令。
注意: 如果在xargs后的命令参数中,路径参数有空格的或tab的,会导致路径无法识别。比如echo "/home/jihan " | xargs -i ls {}就会报错,虽然实际命令ls /home/jihan<空格>没有问题,但是用xargs+i的形式就有问题。
shell调试
- -n 命令,显示shell,不执行,通常用于语法检查。
- -x 命令,我经常用,在执行过程中打印shell脚本执行的真实命令。-v是打印原始命令,不做替换。
- bashdb,类似gdb做调试用,命令:
bashdb --debug your.sh,一下是常用参数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22一、列出代码和查询代码类:
l 列出当前行以下的10行
- 列出正在执行的代码行的前面10行
. 回到正在执行的代码行
/pat/ 向后搜索pat
?pat?向前搜索pat
二、Debug控制类:
h 帮助
help 命令 得到命令的具体信息
q 退出bashdb
x 算数表达式 计算算数表达式的值,并显示出来
!! 空格Shell命令 参数 执行shell命令
使用bashdb进行debug的常用命令(cont.)
三、控制脚本执行类:
n 执行下一条语句,遇到函数,不进入函数里面执行,将函数当作黑盒
s n 单步执行n次,遇到函数进入函数里面
b 行号n 在行号n处设置断点
del 行号n 撤销行号n处的断点
c 行号n 一直执行到行号n处
R 重新启动当前调试脚本
Finish 执行到程序最后
cond n expr 条件断点
查找与当前进程通信的所有进程
- 找到当前进程S的进程pid
- 获取与S通信A的tcp端口号
- 通过A的tcp端口号,获得A的进程pid。这里也可以使用
lsof -i:<port>来查看,速度更快。 - 或者使用
ss -atnp -o 'dport = :7'命令进行查看,更多使用可以看man ss中的示例 - 如果遇到瞬时完成的请求,那么可以先增加防火墙,拦住接收接口,抓包观测到有包到来时,执行命令查看。
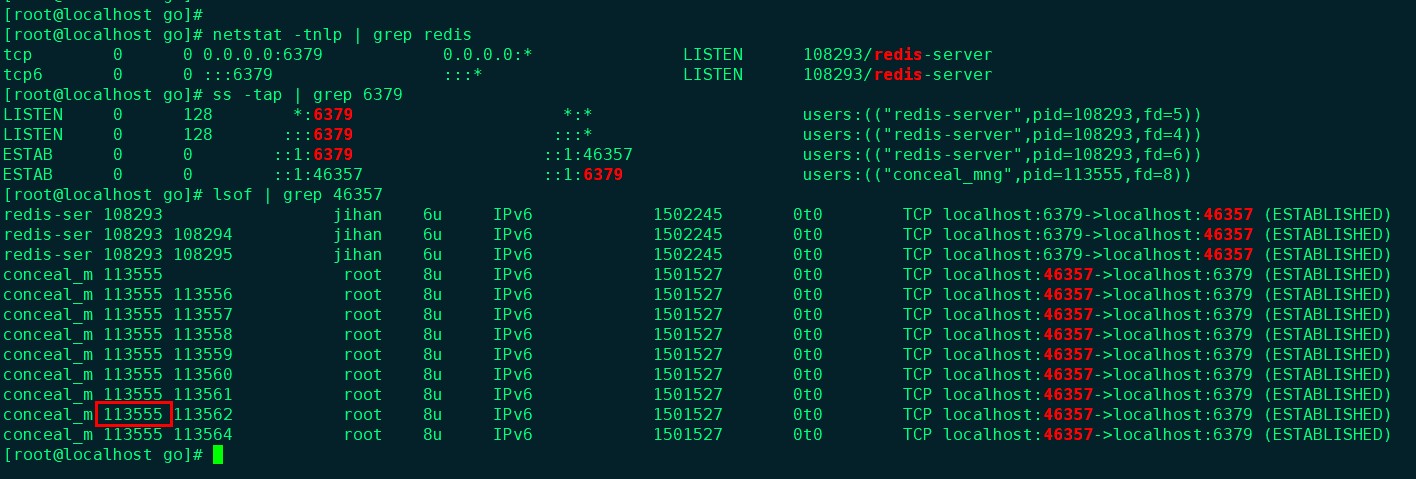
程序执行时的系统调用
strace 是 Linux 中用于监控和篡改进程与内核之间操作的工具。非常强大的工具,能够有效排查程序性能问题,异常操作以及段错误问题。
程序内存检测
valgrind 参考
Linux文件锁定
在root权限下,有可能对某个文件都没有操作权限,可能是使用chattr对其进行锁定,可使用其进行解除。lsattr查看相应属性。参考
Linux 内核小版本升级
小版本,就是 3.10.0-862中-后的东西。而我们进行升级的时候,需要(centos为例,3.10.0-693升级到3.10.0-862):
- 大版本相同的一个设备(3.10.0-693)
- 想要升级的rpm包(3.10.0-862)官方,找不到直接Google搜吧。这个网站很全
yum install kernel-3.10.0-862.9.1.el7.x86_64.rpm- grub2看看启动顺序
grub2-editenv list以及awk -F \' '$1=="menuentry " {print i++ " : " $2}' /etc/grub2.cfg - reboot
需要源码的情况下,执行yum install kernel-devel会自动根据内核版本下载安装源码到/usr/src/kernels中(会下载最新版本的,郁闷)- 需要内核源码的话,从网上搜索对应的源码,执行
yum install kernel-devel-xxxx.rpm安装即可。这个网站很全
linux源码编译
内核模块源码编译安装
用户态的源码编译安装,和普通的其他软件没有什么区别,基本都是make,make install,但是你要进行内核模块的源码构建,那么有如下几种方式:
-
放在源码树以内(例如iptables)。假如我要自定义一个netfilter的模块,而且希望将他存放于/net/netfilter/目录下,那么要注意,在该目录下存在大量的.c源码文件。如果你的模块文件仅仅只有一两个源文件,你可以直接将其放在该目录下,如果你的模块包含的源文件比较多的话,也许你应该建立一个单独的文件夹,用于专门维护你的模块程序源文件。假如创建一个目录名为:mynetfilter/子目录。接下来需要修改/net/netfilter/目录下的Makefile文件:
1
Obj-m += mynetfilter/
这行编译指令告诉模块构建系统,在编译模块时需要进入mynetfilter/子目录。如果你的模块程序依赖于一个特殊的配置选项。比如,CONFIG_ MYNETFILTER_TEST(该选项在编译内核时,执行make menuconfig命令时用于配置该模块的编译选项),你需要修改/net/netfilter/目录下的Kconfig文件
1
2config “MYNETFILTER_TEST”
tristate “netfilter test module”编译内核时,执行make menucofnig之后,我们会在配置菜单上看到此选项,随之,需要修改Makefile文件,用下面的指令替换之前的
Obj-m += mynetfilter/:1
Obj-$(CONFIG_MYNETFILTER_TEST) += mynetfilter/
最后,在/net/netfilter/mynetfilter/目录下添加一个Makefile文件,其中需要添加下面的指令:
1
Obj –m += mynetfilter.o
准备就绪了,现在构建系统会进入到mynetfilter/目录下,将mynetfilter.c编译为mynetfilter.ko模块。
附:如果你只想编译内核中某个模块的ko,也可以cd到该目录,执行:1
make CONFIG_XXX=m –c /kernel/source/location SUBDIRS=$PWD modules
-
内核源码树之外构建(例如ipset)
如果将模块代码放在内核源码树之外单独构建的话,你只需要在你的模块目录下创建一个Makefile文件,添加一行指令:1
Obj-m := mynetfilter.o
如果你有多个源文件只需添加另一行指令:
1
mynetfilter-objs := mynetfiler-init.o mynetfiler-exit.o
模块在内核内和内核外构建的最大的区别在于构建过程。当模块在内核源代码树之外构建时,你必须告诉make如何找到内核源代码文件和基础Makefile文件。通过下面的指令完成上述功能:
1
make –c /kernel/source/location SUBDIRS=$PWD modules
其中,/kernel/source/location/ 即为你配置的内核源代码树的位置。SUBDIRS是你需要编译的模块位置。
Linux 内核模块加载
Linux路由操作
路由:某个ip(某个范围ip)应当到哪个网关去找。网关对应下一条路由。
route命令操作
注意:route命令官方已经废弃,推荐使用ip
route -n
添加默认路由:
route add default gw 192.168.161.11 dev eth0
添加一般路由:
route add -net 192.168.62.11 netmask 255.255.255.0 gw 192.168.1.1
或
route add -net 192.168.62.0/24 gw 192.168.1.1
删除路由:
route del -net 192.168.62.11 netmask 255.255.255.0
或
route del -net 192.168.62.0/24
net表示一个ip或者网段gw表示网关或下一跳路由dev表示对应的出口网卡
ip命令路由操作
ip route list
ip -6 route add <ipv6network>/<prefixlength> dev <device>
ip route add/del <network_ip>/<cidr> via <gateway_ip> dev <network_card_name>
添加默认路由:
ip route add default via 10.92.2.1 dev eth0
添加一般路由:
ip route add 10.0.3.0/24 via 10.0.3.1 dev eth0
删除路由:
ip route del 10.0.3.22 via 10.0.3.1 dev eth0
nm命令操作
mysql 性能优化
sudo、su和sudo -s的差别
relocation error: /usr/lib64/libc.so.6: symbol _dl_starting_up,
relocation error: /usr/lib64/libc.so.6: symbol _dl_starting_up, version GLIBC_PRIVATE not defined in file ld-linux-x86-64.so.2 with link time reference 问题解决
在建立一个错误的软连接到ld-linux-x86-64.so.2时,悲剧就这么发生了。此时大部分命令都不能使用,SSH当然也不能登录了。这个时候一定不要退出终端。
有人说那就把软连接复原吧,可是ln也同样无法使用。。。这时候我们就可以使用可爱的sln命令就可以了,哈哈。
lsn /usr/lib64/ld-2.17.so /usr/lib64/ld-linux-x86-64.so.2
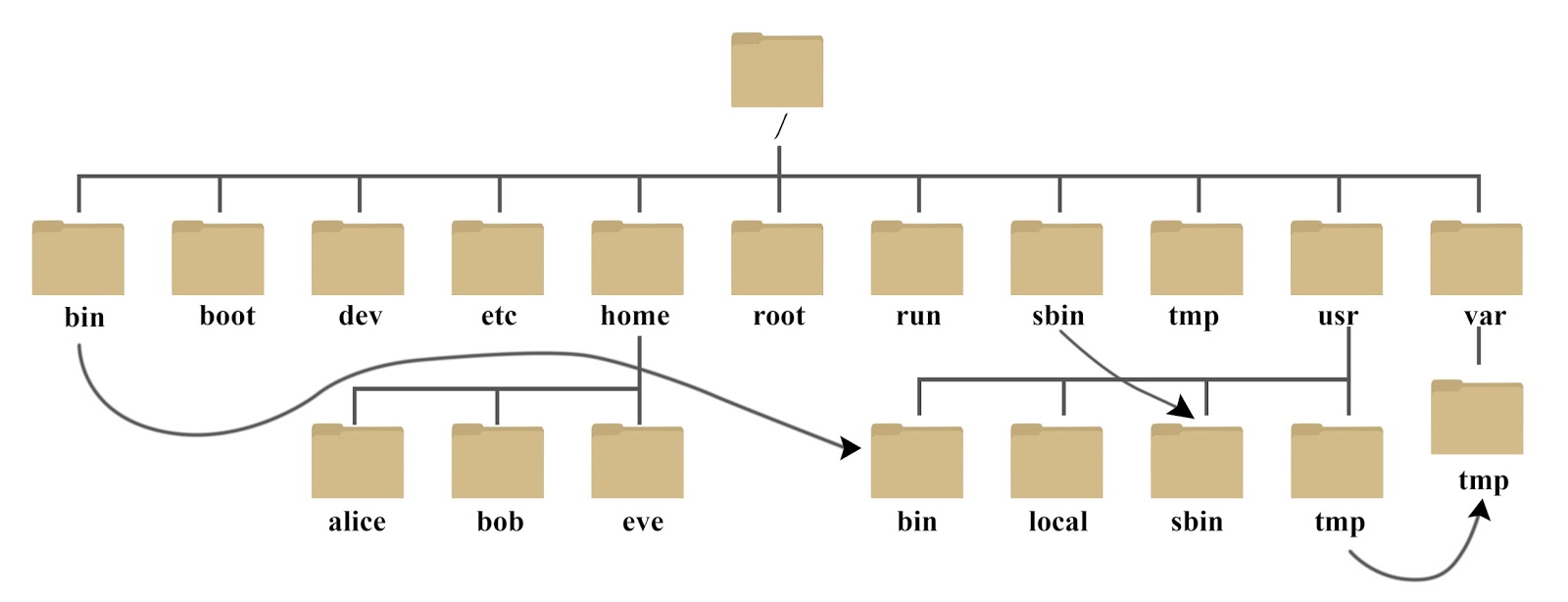
linux死亡操作
随意动/usr/lib64或/lib64下的库,特别是ld、libc之类的,覆盖、移动和删除效果都差不多,基本就是系统爆破级别的。特别注意升级openssl,gcc都容易出现这种问题。附上linux文件目录结构(参考):
Gcc静/动态链接库链接顺序
静态库链接时搜索路径顺序:
- ld会去找GCC命令中的参数-L
- 再找gcc的环境变量LIBRARY_PATH
- 再找内定目录 /lib /usr/lib /usr/local/lib 这是当初compile gcc时写在程序内的
动态库链接时、执行时搜索路径顺序:
- 编译目标代码时指定的动态库搜索路径
- 环境变量LD_LIBRARY_PATH指定的动态库搜索路径
- 配置文件/etc/ld.so.conf中指定的动态库搜索路径
- 默认的动态库搜索路径/lib
- 默认的动态库搜索路径/usr/lib
链接时相互依赖顺序是从右到左,越是底层,越靠后写。例如:
1 | g++ ... obj($?) -l(上层逻辑lib) -l(中间封装lib) -l(基础lib) -l(系统lib) -o $@ |
有关环境变量:
LIBRARY_PATH环境变量:指定程序静态链接库文件搜索路径
LD_LIBRARY_PATH环境变量:指定程序动态链接库文件搜索路径
对于排查链接问题方法:
ldd <your_lib>:查看可执行程序或者动态库运行时的链接库
readelf -d <your_lib>:和ldd类似,不用运行程序,查看可执行程序或动态库ELF
LD_DEBUG=libs ./<your_exe>:查看程序执行时的动态库调度过程。很有用。
ldconfig:它会遍历默认所有共享库目录,比如/lib,/usr/lib等,然后更新所有的软链接,使她们指向最新共享库。替换了新的动态库,有时需要使用该命令来清除search cache
关于动态链接库找不到的问题汇总
指定动态库版本或路径:
-Wl,-rpath,<your_lib_path>: 指定程序运行时动态库链接路径。
将-lxxx直接修改为/you/path/libxxx,可以指定动态库的绝对路径。
参考:
wiki rpath
rpath vs runpath 附加了许多动态库加载的示例。
静态链接与动态链接库的查找顺序
gcc 链接库的顺序问题
gcc/ld: what is to -Wl,-rpath in dynamic linking what -l is to -L in static linking?
Why LD_LIBRARY_PATH is BAD and the correct way to load dynamic libraries
有关linux下的目录
上述有相关的linux目录结构,这里说明一下/tmp目录,在linux系统中,/tmp目录在一定周期或者重启等都有可能删除相应部分符合条件的文件。而删除方法是通过执行定时任务/etc/cron.daily/tmpwatch,此定时任务在系统最小安装的情况下,需要手动安装。
关于系统监控
相对大型系统,都需要进行系统监控。特别针对于微服务系统架构。个人理解需要从三个方面进行监控(另可参考):
- 业务逻辑层,负责统计业务访问状态,访问结果,异常等(常用方式log输出。比如syslog)——通常管理员用户都关注
- 分布式链路追踪,又称为APM。用于追踪一个业务从开始到结束中间每个阶段的执行情况,用于多组件排错非常方便。(opentracing, Zipkin and Jaeger)——通常管理员关注
- 系统整体运行状态,关注系统整体内存,网络,cpu等使用情况。(Prometheus)——管理员关注
关于软件项目方案评估
- 易用性
- 可用性
- 性能
- 安全性
- 可维护性(日志,监控系统)
- 可扩展性
tcpdump
非常强大的抓包工具。全面使用教程:https://colobu.com/2019/07/16/a-tcpdump-tutorial-with-examples/
linux环境加载
- 登录式shell加载:/etc/profile -> /etc/profile.d/*.sh -> /etc/environment -> /.bash_profile(网上也说是/.profile,但我没发现) -> ~/.bashrc -> /etc/bashrc
- 非登录式bash shell窗口: ~/.bashrc ->/etc/bashrc -> /etc/profile.d/*.sh
其中系统环境在/etc/environment中配置,但一般不要修改它,如果你需要修改系统环境,对每个用户都生效,可以在/etc/profile.d/下增加sh文件。
如果是个人的环境变更,可以修改~/.bash_profile,如果需要执行一些公共方法,或者别名(alias)之类的,可以在~/.bashrc中增加。
设计模式的六大原则:
参考
单一职责原则:
即一个类只负责一项职责
里氏替换原则:
类B继承类A时,除添加新的方法完成新增功能P2外,尽量不要重写父类A的方法,也尽量不要重载父类A的方法。
依赖倒置原则:
高层模块不应该依赖低层模块,二者都应该依赖其抽象;抽象不应该依赖细节;细节应该依赖抽象。
接口隔离原则:
一个模块不应该依赖它不需要的接口;一个类对另一个类的依赖应该建立在最小的接口上。
迪米特法则:
一个对象应该对其他对象保持最少的了解。
开闭原则:
一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。
即:当软件需要变化时,尽量通过扩展软件实体的行为来实现变化,而不是通过修改已有的代码来实现变化。
mysql-bin-log:
- 只有特定版本以上支持binlog
- 有三种binlog记录模式:row,statement,mixed。详情
unknown variable 'default-character-set=utf8'解决方法:增加参数--no-defaults- row模式下查看详细sql语句,在mysqlbinlog下增加
-v参数。 - mysql5.7.30对应的mysqlbinlog版本是3.4,可以通过
mysqlbinlog --version查看 - binlog的查看方式参考
linux下载离线rpm包
https://www.cnblogs.com/daodaotest/p/12452290.html#5
git submodule
注意:
- 参考中的所有命令,最好都在项目根目录执行。否则容易出现看起来不生效的问题。
- 执行
git submodule add <url>生成的对应子模块目录,要一并提交,不要删除。 - 如何删除submodule:How do I remove a Git submodule
git merge提前检测冲突
排查cpu占用高,或进程死锁问题
- 使用
top查看当前系统状态。命令用法,free命令协助查看内存占用。free命令详解(-h已经不行了,要-m) - 使用
strace打出当前进程的系统调用,分析是什么系统调用导致异常。 - 多线程的情况下,可以使用
pstack打印每个线程的堆栈信息,对死锁问题有很大帮助。 - 可以考虑使用
gdb调试跟踪进程(会影响进程正常工作),发现更详细问题。
关于unix sock和localhost tcp对比
unix domain sockets vs. internet sockets
Go和Rust的区别
git代码仓库管理
网络快速学习
https://mp.weixin.qq.com/s/IOCUGXjKCQV8qPycxhM2YA
路由中有个类似:192.168.88.0/24 dev eth1 scope link这种路由,如果你ping 192.168.88.0/24网段的ip,那么会进行路由匹配,命中改路由,认为这个是本地路由,直接进行本地广播链接
为什么需要三次握手?
- 第一次握手:客户发送请求,此时服务器知道客户能发;
- 第二次握手:服务器发送确认,此时客户知道服务器能发能收;
- 第三次握手:客户发送确认,此时服务器知道客户能收。
客户端TIME_WAIT为什么需要等待2MSL?
- 最后一个报文没有确认;
- 确保发送方的ACK可以到达接收方;
- 2MSL时间内没有收到,则接收方会重发;
- 确保当前连接的所有报文都已经过期。
TCP四次挥手,为什么是四次?
关于为何要四次挥手
Go自动化测试
一个 Golang 项目的测试实践全记录
GoLang快速上手单元测试
GoMock:
- 用于接口,测试方法是实现你某个函数的接口,来测试你上次业务逻辑。httpmock就是自定义实现
Transport来实现。 - 可以无侵入式测试业务逻辑,可脱离数据库,网络等底层带有
interface的依赖
httptest:
官方提供的一个http测试桩的库,在依赖第三方服务时,可使用该测试脱离第三方测试。
使用标准库httptest完成HTTP请求的Mock测试
GoConvey:
严格上来说,只是一个用于test的ui页面展示工具,方便查看代码的测试覆盖情况和通过情况等。
sqlmock
用于提供数据库的mock
gomonkey
做函数和变量替换。进行打桩
自动化测试常见场景:
一文说尽Golang单元测试实战的那些事儿
单元测试:
使用官方推荐的test即可,保证逻辑拆分以及每个模块都写上单元测试。
表格驱动测试:
表格驱动测试通过定义一组不同的输入,可以让代码得到充分的测试,同时也能有效地测试负路径。比如在golang中使用t.Run(name string, subTest func(t *T))来测试多种情况。
可以使用更强大直观的GoConvey在配置多个测试用例
http接口依赖:
可使用httptest解除依赖
依赖底层接口或者第三方函数:
接口依赖,可以使用GoMock解决
第三方函数依赖,可以使用gomonkey进行函数替换解决
数据库依赖:
mysql依赖:可使用sqlmock
redis依赖: 可以使用miniredis搭建一个微型服务器。
通常数据库都是以接口形式实现的,也可以通过GoMock来自定义做自定义返回。
查看哪个进程向我发送了信号
strace -p 59951 -e 'trace=!all'
缓存技术
- FIFO
- LFU
- LRU
- LUR-K: LRU-2常用
- 2Q: FIFO+LRU
linux 向本地syslog发数据
logger详解
示例:logger -i -t "my_test" -p local3.notice "test_info"
证书常用命令
-
pfx格式转crt格式(未验证,有问题)
1
2
3openssl pkcs12 -in myssl.pfx -nodes -out server.pem
openssl rsa -in server.pem -out server.key
openssl x509 -in server.pem -out server.crt -
crt格式转pfx
openssl pkcs12 -export -in server.crt -inkey server.key -out server.pfx -
crt的key增加密码
openssl pkey -in server.key -out server_1.key -passout pass:"12345678" -
查看pem证书
1
2
3openssl rsa -noout -text -in myserver.key
openssl req -noout -text -in myserver.csr
openssl x509 -noout -text -in ca.crt
kill -9无法杀死的情况
参考
正常情况kill命令发送的是SIGTERM信号,表示用户想要中断,进程可以优雅的退出。
而kill -9发送的是SIGKILL信号,表示直接杀死进程,但是有两种情况是杀不掉的:
- 该进程是僵尸进程,此时进程已经释放所有的资源,但是没有被父进程释放。僵尸进程要等到父进程结束,或者重启系统才可以被释放。
- 进程处于“核心态”,并且在等待不可获得的资源,处于“核心态 ”的资源默认忽略所有信号。只能重启系统。
进程通信的各种情况,以及适用场景
性能排查工具大全
wireshark解密https:
secret
参考
- 证书导入:
- 首先导出pkcs12类型的证书(会要求输入密码):
openssl pkcs12 -export -in gateway.pem -out key.pkcs12 - 在wireshark中选择编辑->首选项->协议->tls,选择RSA key list:

- 导入服务器证书:

- 首先导出pkcs12类型的证书(会要求输入密码):
- 环境配置导入:
- 设置环境变量:SSLKEYLOGFILE=路径\sslkey.log
- wireshark中配置相应链接文件:

方案调研方法
- 明确需求
- 从网上查找对应的解决方案:
- GitHub的topic
- 工具索引对比类网站stackshare,LibHunt
代码覆盖率统计
linux下C死锁排查
https://blog.csdn.net/zsiming/article/details/126695393
valgrind使用
内存泄漏分析,性能分析:https://zhuanlan.zhihu.com/p/92074597
gdb十六进制打印
1 | x /5xb ptr |
格式: x /nfu
参数说明:
n表示要显示的内存单元的个数
f表示显示方式, 可取如下值
x 按十六进制格式显示变量。
d 按十进制格式显示变量。
u 按十进制格式显示无符号整型。
o 按八进制格式显示变量。
t 按二进制格式显示变量。
a 按十六进制格式显示变量。
i 指令地址格式
c 按字符格式显示变量。
f 按浮点数格式显示变量。
u 表示一个地址单元的长度
b 表示单字节,
h 表示双字节,
w 表示四字节,
g 表示八字节
基于nc的反向代理
1 | mkfifo nc_proxy |
-k 表示可以建立多条sock
上述命令含义:
上行:在当前设备上建立12345监听,接收数据输出到管道nc_proxy,nc_proxy作为nc dst_ip dst_port < nc_porxy输入
下行:nc dst_ip dst_port < nc_porxy命令输出下行数据,通过|输入给nc -k -l 0.0.0.0 12345 > ./nc_porxy
堆栈段偏移排查
对于一些堆栈溢出的日志,可以通过下面命令排查:
1 | addr2line -e [进程] [相对地址] |
示例:
1 | ./lb(dumpBacktrace+0x44f)[0x6f32fd] |
1 | $ addr2line -e ./lb 0x47a914 |
zsh快捷键
基本命令:
ctrl + u:清空当前行
ctrl + a:移动到行首
ctrl + e:移动到行尾
ctrl + f:向前移动
ctrl + b:向后移动
ctrl + p:上一条命令
ctrl + n:下一条命令
ctrl + r:搜索历史命令
ctrl + y:召回最近用命令删除的文字
ctrl + h:删除光标之前的字符
ctrl + d:删除光标所指的字符
ctrl + w:删除光标之前的单词
ctrl + k:删除从光标到行尾的内容
ctrl + t:交换光标和之前的字符
命令自动补全(zsh-autosuggestions):
ctrl + →:到自动补全命令的下一个单词
→:到自动补全命令末尾
const
const char *ptr;: const 修饰的是*ptr,意味着指针指向的数据不能修改
char const *ptr;:同const char *ptr;
char * const ptr;:const 修饰的是ptr,意味着指针本身不能修改