工作需要,了解了一下Net filter的工作原理。(•̀⌄•́)
—— By Jihan
源码的版本:linux-3.10.0-1127.18.2.el7 (centos)
包含netfilter的基本介绍,iptables规则介绍及使用,netfilter实现原理,自定义match实现,链接跟踪实现、ipset和iptables联动和ipset实现
简介
Netfilter,在Linux内核中的一个软件框架,用于管理网络数据包。不仅具有网络地址转换(NAT)的功能,也具备数据包内容修改、以及数据包过滤等防火墙功能。利用运作于用户空间的应用软件,如iptables、ebtables和arptables等,来控制Netfilter,系统管理者可以管理通过Linux操作系统的各种网络数据包。
iptables:
Netfilter中最为常用的一种网络数据包过滤方式——IP包过滤,我们也将重点介绍这种过滤方式。用户在使用iptables时需要超级用户权限,以及内核模块需要Xtables模块做支撑。iptables只能处理ipv4,对应的ipv6则使ip6tables来处理。
ebtables
ebtables 是以太网桥防火墙,以太网桥工作在数据链路层,ebtables 主要用来过滤数据链路层数据包。使用 ebtables 可以实现 filtering 、NAT 和 brouting。过滤根据 MAC 头包括 VLAN ID 等信息确定是否丢弃该帧。MAC NAT 可以修改 MAC 源和目的地址。Brouting 意为 bridge or route,根据规则确定应该将数据帧路由给上层(iptables)还是通过网桥转给其它的接口。
ebtables 和我们熟悉的 iptables 很像,也有规则(rules)、链(chains)和表(tables)的概念。ebtables 使用规则确定应当对数据帧执行什么动作。规则按照不同的链分组,不同的表中包含不同的链。在 ebtables 中有三张表:filter、nat 和 broute,分别对应其三大功能模块。
需要注意的是如果一个以太网接口 eth1,它并没有桥接到网桥上,此时,从 eth1 进来的数据包不会走到 ebtables 中。在 bridge check 点,会检查数据包进入的接口是否属于某个桥,如果是则走 ebtables,否则直接走 iptables。也就是说,ebtables 只对桥接网络生效。
arptables
arptables 是运行在用户空间的应用软件,通过控制Linux内核netfilter模块,来管理地址解析协议(arp)数据包的过滤和转发。
arptables基于iptables开发,使用时也与iptables有些类似,都有“表(tables)”、“链(chain)”和“规则(rules)”三个层面。
但是arptables功能较单一,仅有filter一个表。并且,也只有INPUT(从内核2.4版)、OUTPUT(从内核2.4版)和FORWARD(从内核2.6版)三个内建链。arptables的主要用途之一是防范ARP欺骗。
基础结构
Netfilter 包含了一组内核钩子 API ,周边内核组件可以使用这些钩子在网络栈中注册回调函数。每一个在网络栈中流通的包到达相应的钩子时,就会触发相应的回调函数,从而能够完成包过滤、网络地址(端口)转换和网络包协议头修改等各种操作。
Netfilter 提供了五种钩子:
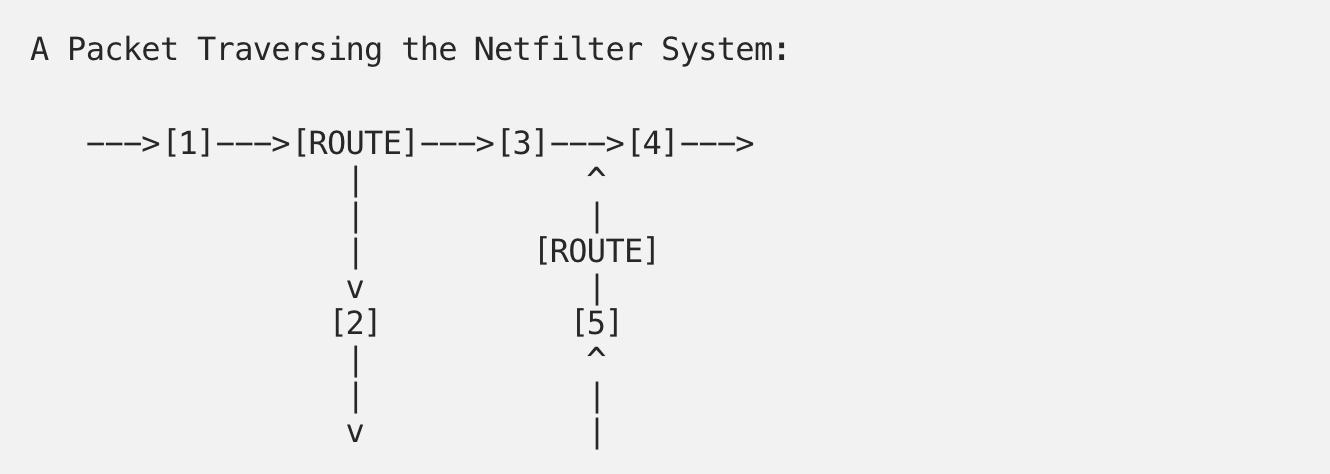
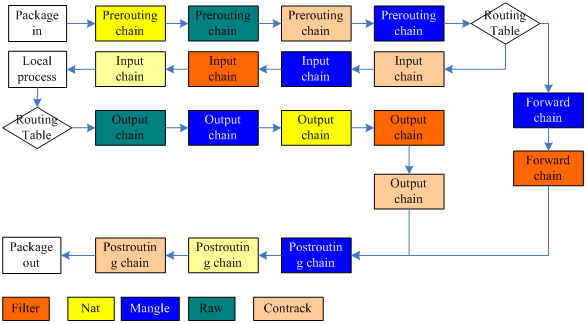
NF_IP_PER_ROUNTING— 当数据包到达计算机立即触发。NF_IP_LOCAL_IN— 当数据包的目的地就是当前计算机时触发。NF_IP_FORWARD— 当数据包目的地址是其它的网络接口时触发。NF_IP_POST_ROUTING— 当数据包即将从计算机发出时触发。NF_IP_LOCAL_OUT— 当数据包由本地生成并发向外部时触发。
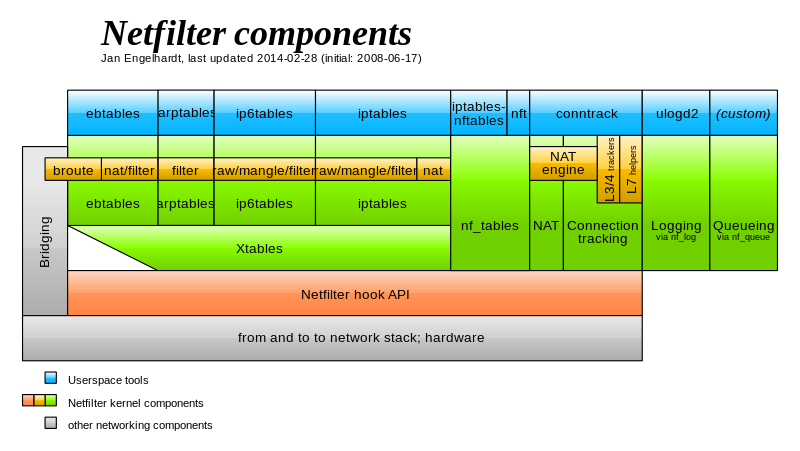
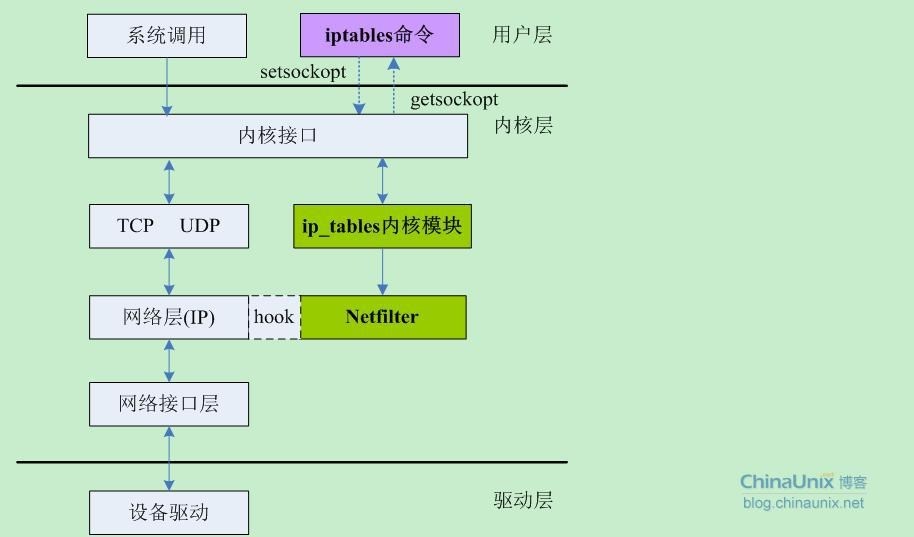
基于 Netfilter 钩子 API 实现的内核模块主要有 ebtables、arptables、ip(6)tables、nf_tables、NAT、connection tracking 等。如下架构图:
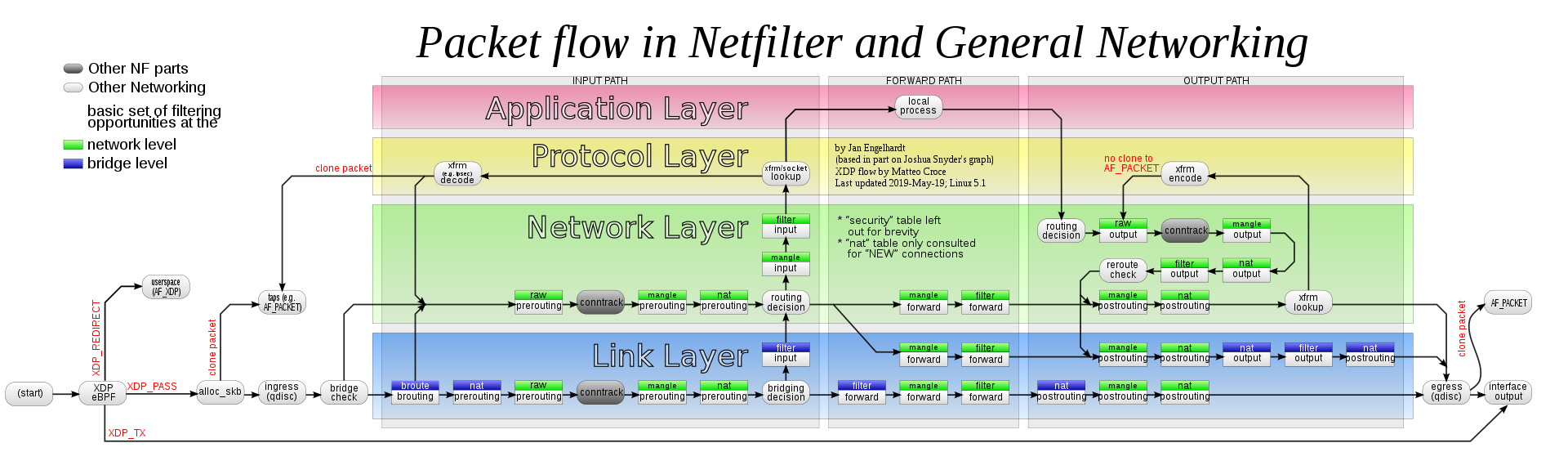
而数据包在整个Netfilter中的数据流如下图:
建立规则和链
通过向防火墙提供有关对来自某个源、到某个目的地或具有特定协议类型的信息包要做些什么的指令,规则控制信息包的过滤。 通过使用 netfilter/iptables 系统提供的特殊命令 iptables ,建立这些规则,并将其添加到内核空间的特定信息包过滤表内的链中。关于添加/除去/编辑规则的命令的一般语法如下:
1 | iptables [-t table] command [match] [target] |
用法
| 选项 | 描述 |
|---|---|
| -A --append | 将一个或多个规则添加到所选链的末尾。 |
| -C --check | 检查与所选链中的规范匹配的规则。 |
| -D --delete | 从所选链中删除一个或多个规则。 |
| -F --flush | 逐个删除所有规则。 |
| -I --insert | 将一个或多个规则作为给定的规则编号插入所选链中。 |
| -L --list | 显示所选链中的规则。 |
| -n --numeric | 以数字格式显示IP地址或主机名和邮政编号。 |
| -N --new-chain |
创建一个新的用户定义链。 |
| -v --verbose | 与list选项一起使用时提供更多信息。 |
| -X --delete-chain |
删除用户定义的链。 |
示例
1 | // 列出对应规则 |
跟踪iptables规则匹配
这里有两种方式跟踪一个包匹配了哪些规则。参考
- 跟踪计数器
观察iptables -nvL INPUT返回的第一列pkts是否增长了,可以简单的判断规则被匹配。 - 可以在iptables规则前后添加日志,通过观察日志来跟踪规则
1
2
3
4#添加日志记录在INPUT第一个规则,并且设置日志前缀为 IPTABLES LOG:
iptables -I INPUT -j LOG --log-prefix "IPTABLES LOG: "
#查看日志, 这里可能会出现消息延迟的问题。
dmesg|grep "IPTABLES LOG:"
规则构成
在我们执行一个iptables命令的时候,往往达到的效果,就是在某个表的某个链中添加某一条规则。而参与这条规则构成的包括表(table)、链(chain)、匹配(match)和目标(target)。下面将详细介绍这几个部分。
表(table)
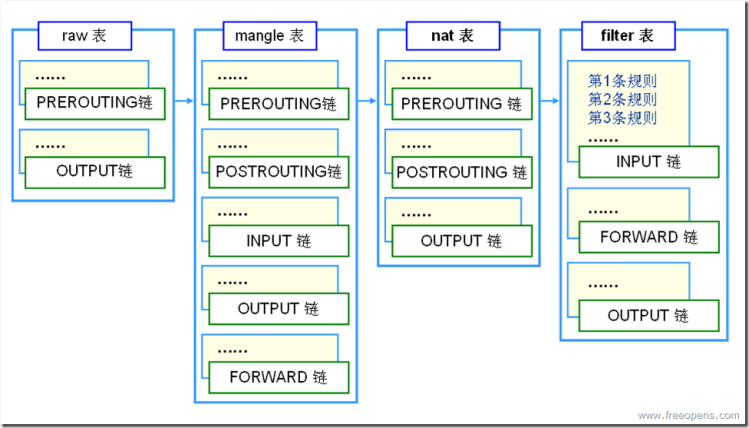
iptables里包含了4张表,分别是filter、nat、mangle和raw表。而表的作用在于存放规则,比如我们平时执行iptables -nL会得到类似的结果:
1 | Chain INPUT (policy ACCEPT) |
(policy XXX)表示着默认策略。表中包含的链,表示着表里的规则可生效的链范围。表和链有着如下关系:
链(chain)
如果表是存放规则的地方,而链就是决定规则执行的时机,iptables中的5条链PREROUTING、INPUT、OUTPUT、FORWARD和POSTROUTING。而执行的位置也在简介中的netfilter hook原理中给出了。链把相应的表按照一定的顺序串起来,找出表里对应的规则进行执行。
匹配(match)
-m或--match命令所做的工作,当然这部分我们称为扩展匹配,-s -i所执行的也是匹配工作,称为通用匹配。
通用匹配
类似-s这类的通用匹配,通常在用户态代码,和内核代码都包含了,不需要额外加载module。在iptables规则下发里,也是属于附加的基本参数。
扩展匹配
首先,我们在使用扩展匹配的时候,可以使用帮助文档:iptables -m the_match_you_want --help。扩展模块要工作的时候,都需要进行模块匹配,用户态匹配对应的libipt_xxx或libxt_xxx。内核态匹配对应的xt_xxx。比如我们使用的-m state在iptables命令执行时,会找libxt_state.so的动态库,规则下发到内核的时候,内核会找对应的xt_state.ko模块。具体源码实现后续会说明。
如果想自定义扩展匹配,那么需要写内核模块代码(参考内核模块源码的xt_multiport.c)和用户态模块代码(参考libxt_multiport.c)以及定义的头文件(参考xt_multiport.h)
目标(target)
-j所做的工作,在包匹配成功后,就会执行-j后面的动作,来对包进行处理。
通用目标
DROP,ACCEPT,QUEUE和RETURN这几个属于通用匹配,他们同样以模块的形式进行加载和工作,对应的模块是standard
扩展目标
扩展目标和扩展匹配也是相似的工作原理,都是进行模块加载。如果要写自定义模块,需要内核模块代码(参考xt_LOG.c)和用户态模块代码(参考libipt_LOG.c)和头文件(参考xt_LOG.h)
Netfilter源码实现
Netfilter的整体工作方式类似下图:
基本数据结构
由于本人也没有精读源码,所以也只能介绍个大概,一切以源码为准。
xt_table与xt_table_info
xt_table是Netfilter的核心数据结构,它包含了每个表的所有规则信息,以及匹配处理方法。数据包进入Netfilter后通过查表,匹配相应的规则来决定对数据包的处理结果。下面是xt_table的完整定义(在X_tables.h中):
1 | struct xt_table { |
每个成员意思见上文定义中的注释,个别成员说明如下:
valid_hooks:所支持的hook点类型,决定后续注册hook操作的位置。比如filter表的valid_hoos被指定为:(1 << NF_INET_LOCAL_IN) | (1 << NF_INET_FORWARD) | (1 << NF_INET_LOCAL_OUT)),即在NF_INET_LOCAL_IN、NF_INET_FORWARD、NF_INET_LOCAL_OUT三处注册hook操作;
private:xt_table的数据区,包含了所有规则和规则处理方法等信息。xt_table_info详细信息见下文。
xt_table的所有数据都存在private的成员变量中,private是结构体struct xt_table_info,其定义如下:
1 | struct xt_table_info { |
重要成员说明:
hook_entry: 不同hook点的规则的偏移量;
entries: 规则存储的入口,为可变区域,必须放在结构末尾。entries本质上是ipt_entry结构。关于ipt_entry定义和成员介绍见下文。
ipt_entry
ipt_entry结构是对规则的描述,其定义如下:
1 | /* This structure defines each of the firewall rules. Consists of 3 |
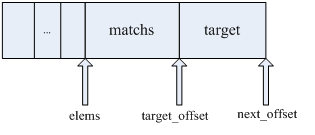
成员elems中,保存了一条规则的所有匹配(matchs),以及匹配后的处理操作(target)。在Iptables.c中,generate_entry()方法新建一个ipt_entry,可以看到如何将matchs和target添加到ipt_entry中的:
1 | static struct ipt_entry * |
见上文的程序片段,ipt_entry的空间占用为:ipt_entry结构自身的size,加之所有match的size总和,加之target的size。填写elems时,首先将所有的match依次拷贝到elems指向的存储位置,紧接着将target拷贝到其后。下图是ipt_entry存储示意图:
nf_hook_ops
nf_hook_ops用于注册一个hook操作,它主要包含了hook操作执行函数、hook类型,以及优先级。我们可以认为,一个nf_hook_ops表征了一个表的一条链,因为它与一个表的一个hook类型唯一对应。其完整定义如下:
1 | struct nf_hook_ops { |
重要成员说明:
hook:hook操作函数;
owner:所属的表;
hooknum:hook类型;
priority:优先级,决定同一hook点,链(不同表在同一个hook点的链)的执行次序。
ipt_replace
结构主要用于iptables的规则下发,在setsockopt进行规则下发时以此结构体作为传输数据。
1 | /* The argument to IPT_SO_SET_REPLACE. */ |
重要成员说明:
entries:对应的扩展matches和target的数据集合,其组成方式就是上面对应ip_entry的介绍。
Netfilter内部数据包处理
在简介中已经提到了netfilter的hook机制和hook点,现在我们来了解下具体流程。
首先,内核在收到ip包后,会进行一系列的操作,而hook的位置如下:
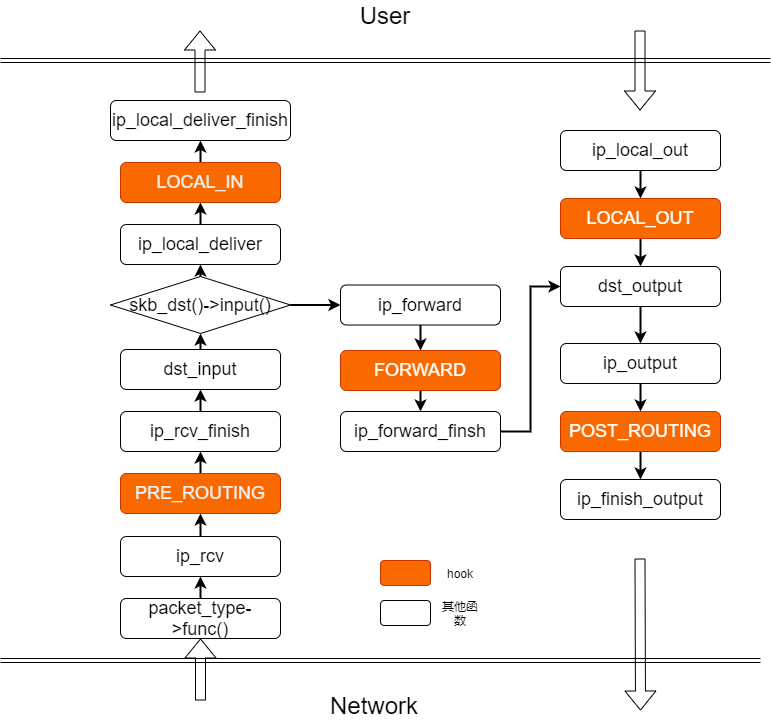
当我们对应的hook点有相应的注册函数时,就会进行相应的注册的hook函数调用:
1 | /* |
ip_input.c
而实际的hook处理流程如下:
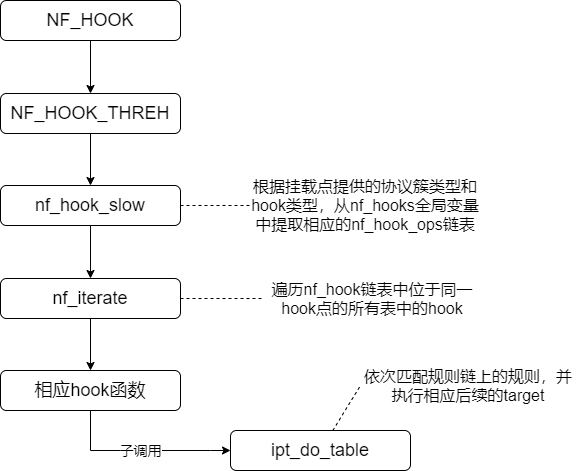
这里主要的实现函数nf_hook_slow
1 | int nf_hook_slow(struct sk_buff *skb, struct nf_hook_state *state) |
这里的nf_hooks[state->pf][state->hook]中,state->pf是对应的协议,比如NFPROTO_IPV4, state->hook表示hook的点,比如NF_INET_LOCAL_IN。而nf_hooks是一个全局变量,包含了所有的注册hook。
在进入到ipt_do_table函数后,会进行包的匹配和处理,流程如下:
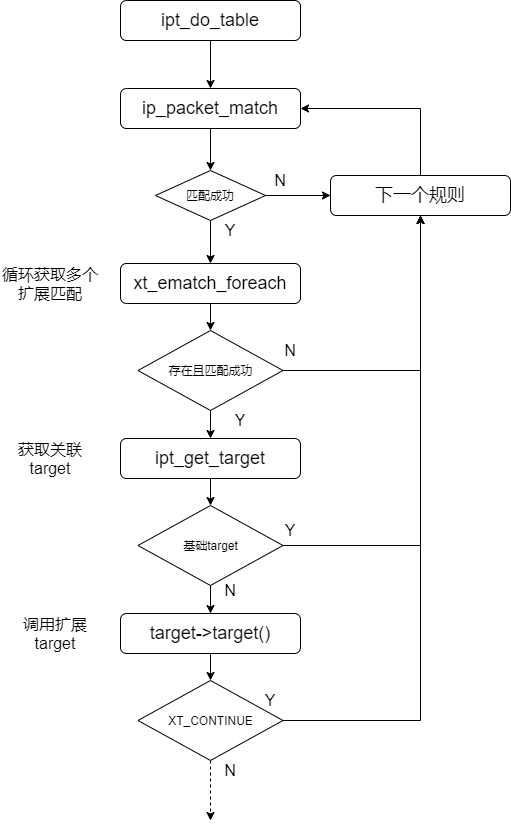
ipt_do_table会先匹配基本match,再匹配扩展match,匹配成功后,进行基础target或扩展target的处理。如果匹配不成功,则会一直匹配直到所有matches匹配完。这也导致了iptables规则在命中一条规则后,后续的规则都不会再进行匹配了(除非你target指向其他链)。
内部数据包处理大概如上所说,但是我们仍然抱有疑惑,hook函数哪里来?扩展match怎么生效等。这就要归功于netfilter的注册机制。
Netfilter模块注册
模块注册的时机是在模块加载的时候,而模块加载分系统启动时加载,即系统启动时加载netfilter以及编译到内核的模块。
而没有编译到内核,而是以独立模块存在的netfilter模块,则会在规则下发的时候,会根据你传入的match或target名称到对应的路径下寻找,并载入模块。
netfilter在设计的时候,就设计了强大的模块加载机制,因此也表现出强大的扩展性。
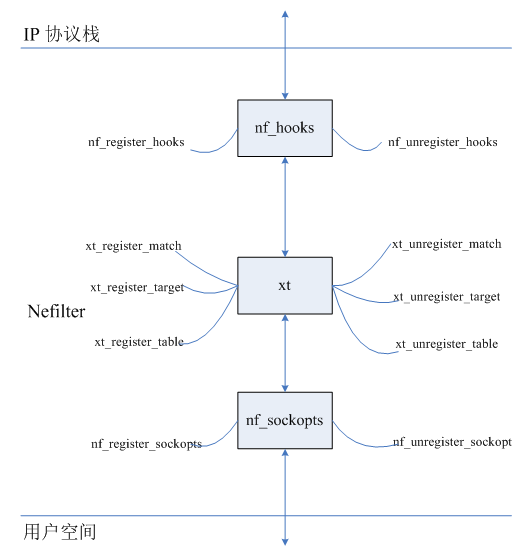
本质上,模块加载结构都是相似的。我们就以iptable_filter.c为例,讲解一下hook的注册过程。

对应的部分iptable_filter.c代码:
1 | static const struct xt_table packet_filter = { |
netfilter注册的逻辑依赖内核模块注册。内核模块加载的时候,会自动调用module_init,在iptable_filter中,调用iptable_filter_init,执行xt_hook_link函数,将packet_filter全局量挂载到nf_hooks全局量。实际包过滤的时候,就会根据nf_hooks来调用注册的hook。
以上就是hook的注册过程,实际在看源码中,match和target等注册过程也是类似的,通过module_init将模块文件的变量注册到全局量中。
iptables规则下发
内核空间与用户空间的数据交互通过getsockopt和setsockopt来完成,这个两个函数用来控制相关socket文件描述符的的选项值。先来看这两个函数的原型:
set/getsockopt(2)函数的基本使用格式为:
1 | int setsockopt(int sockfd, int proto, int cmd, void *data, int datalen) |
在调用setsockopt函数时,实际执行的流程如下:
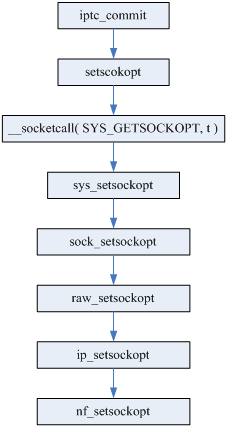
上图中,从setsockopt()到ip_setsockopt()是常规的setsockopt调用流程;在新的流程中,Netfilter加入的自己的处理函数nf_setsockopt()。
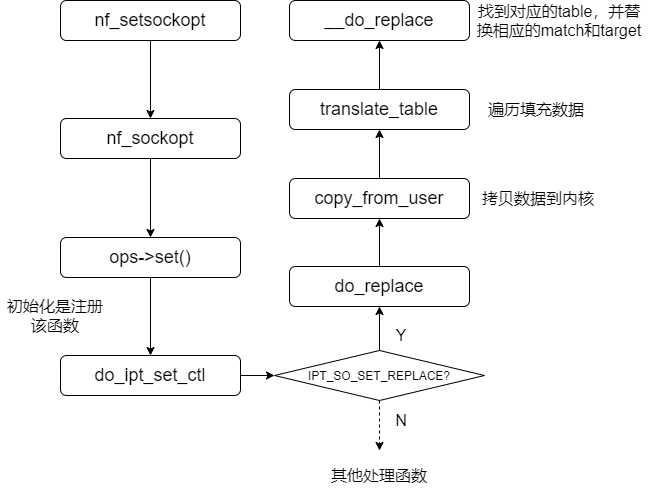
上图中,核心函数do_replace,进行的数据拷贝传输,源码如下:
1 | static int |
从源码可以看到,iptables和内核间的通信,就是通过调用copy_from_user函数进行数据拷贝来完成的。而拷贝的核心数据结构,就是上面介绍过的ipt_replace结构。
至此,Netfilter源码实现的主要流程就介绍完了,更多的细节可自行阅读源码。
自定义match
主要是为了练习,功能就是命中后打印输出一下。
要实现一个iptables的自定义功能,那么,我应该产生三个文件libipt_xx.c、ipt_xx.c和ipt_xx.h(ipt更换为xt一样有效),并放到对应目录中:
1 | ipt_xx.c -> /<linux-kernel-src>/net/ipv4/netfilter/ |
然后再分别编译内核部分ipt_xx.c和ipt_xx.h源码及用户部分libipt_xx.c源码。
环境准备
内核源码下载
通用的linux内核源码的下载
centos/redhat的内核在上面找不到对应的,他们是自己维护的版本,下载方法如下:
1 | # 先复制及设定 centos-common 源码 |
如果你对特定分支感兴趣,也可以下载特定分支:
1 | git clone -b c7 --single-branch https://git.centos.org/rpms/kernel.git |
这里的内核源码也包含了Netfilter的内核源码。
iptables源码:
本文使用的是iptables v1.14.21版本,对应的源码也是这个版本 下载
自定义match源码
内核部分:xt_test.c
1 |
|
用户部分:libxt_test.c
1 |
|
头文件:xt_test.h
1 | /* SPDX-License-Identifier: GPL-2.0 WITH Linux-syscall-note */ |
编译
首先把对应的文件放到对应的位置:
1 | xt_test.c -> /<linux-kernel-src>/net/ipv4/netfilter/ |
用户态源码编译:
1 | ./autogen.sh |
内核源码编译:
1 | cd <your_kernel_src_path>/net/netfilter |
如果出现No rule to make target 'tools/objtool/objtool'的错误:
yum install kernel-headers kernel-devel -y- 找到
/usr/src/kernels/下安装的tools/objtool/objtool/objtool,将可执行文件拷贝到你的内核源码对应目录。 - 重新执行make
测试
-
先把编译得到的
xt_test.ko放到/usr/lib/modules/3.10.0.xxxx/kernel/net/netfilter/目录下。 -
添加iptables规则:
1
/usr/local/iptables/sbin/iptables -A INPUT -p tcp -m test --source-ip <ip> -j DROP
-
使用你配置了的
<ip>地址的机器来访问目标机器(tcp) -
dmesg命令来查看打印输出的消息。
如果出现Couldn't load match 'test11':No such file or directory证明你用户态代码,没有找到你编译的模块。
如果出现iptables:No chain/target/match by the name证明你内核相应的模块没有嵌入。
如果dmesg没有显示出你想要的信息,可能是输出日志级别不够,尝试:dmesg -n 7;或者是存在缓存,尝试删除原有iptables规则,重新配置,之前的日志消息就打印了。
链接跟踪(conntrack)
功能就是给链接做标识。这一章节主要都是参考(也就是抄[狗头])Netfilter链接跟踪简介(想看更详细内容最好看原文,我这里只是简单截取了主要核心部分,就不重复copy了),他其他的netfilter相关的解析也写的挺好,建议去看看。
conntrack介绍
我们期望一种场景,即外网无法访问内网,但是内网能够访问外网。但配置了拒绝所有外网来的数据包以后,内网访问外网返回的包也无法进入内网,导致内网访问外网失败。因此我们可以利用conntrack(链接跟踪)来解决这一问题。
通用的数据访问方式分两种:
- TCP这种面向连接的协议,源和目的的连接终止时,状态防火墙通过检查TCP头的控制标记来跟踪整个过程,并动态地将该连接从状态表中删除。
- DP和ICMP不是面向连接的协议,无法通过报文来判断连接是否终止。状态防火墙会把将UDP流量看成是有连接的,通过在状态表中设置一个定时器,来定期的老化删除一些无用连接。
期望连接:
有一些协议,连接时会分为控制连接和数据连接,我们把数据连接称为是控制连接的期望连接。
我们以tftp协议为例来说明一下期望连接:

如果,客户端先发起连接,使用熟知的69端口。因为69端口是分给了tftp server的,tftp server接收到连接请求后,会自己申请一个server主机上未用的端口1235(因为tftp server的69端口还需要接收其他client发来的连接请求,所有不能使用69来传输数据),给tftp client发送回应。以后client和server就使用端口1235来进行通信了。
现在来看,上面连接是两条不同的连接。我们把第二条连接是其一条连接的期望连接。
比如防火墙上只放开了目的端口号69的访问,当内网访问外网的tftp server时,回应报文就会被拦截,导致tftp 功能失效。状态防火墙提出期望连接,当回应报文根据目的端口号发现该回应是已存在连接的期望连接,防火墙放过该回应报文,这样tftp功能OK。
做个实验:
在一台主机上配置如下规则:
1 | iptables -P INPUT DROP //丢弃所有到本机的报文 |
这时把该主机当tftp client,从tftp server下载东西是无法下载的。
1 | iptables -A INPUT -m conntrack --ctstatus EXPECTED -j ACCEPT//放行期望连接 |
这时tftp功能OK。
因此,为了满足上述需求,链接跟踪实现了以下功能:
- 建立一张连接状态表,来存放连接记录
- 连接状态表中,有定时的垃圾回收机制
- 根据报文进行连接状态的建立及对已有连接状态的更新
- 期望连接的建立和关联
- 在连接跟踪上需要提供易于扩展的接口,来实现用户自定义的一些功能。
下面本文将从两个方向来描述链接跟踪,一是从模块扩展上,模块如何注册到conntrack中,提供报文的处理方法;第二是数据流上,报文时如何一步步的在netfilter框架中流动,被conntrack处理的。
conntrack标识
连接跟踪是根据报文的L3,L4层头信息来标识一条连接的,而这些标识需要一个数据结构来进行定义和存储。改数据结构包含了一条连接的全部信息,并且链接跟踪的查找,建立,关联和更新都是依据该数据结构,我们称该数据结构为元组。
元组数据结构:
1 | struct nf_conntrack_tuple |
从上面数据结构定义看,标识一条连接的元组为:
TCP 源IP,源端口,L3协议类型,目的IP,目的端口号,L4协议类型
UDP 源IP,源端口,L3协议类型,目的IP,目的端口号,L4协议类型
ICMP 源IP,L3协议类型,目的IP,id,type,code,,L4协议类型
conntrack数据结构:
一个连接包含正反两个方向的两条报文流.
1 | struct nf_conn { |
每个struct nf_conn实例代表一个连接。每个skb都有一个指针,指向和它相关联的连接。
1 | struct sk_buff { |
conntrack的存储:
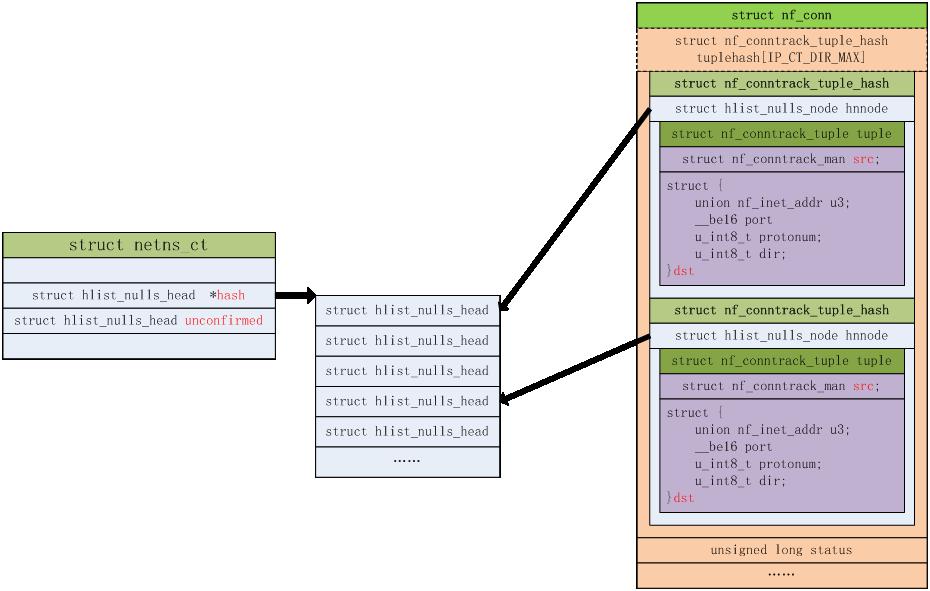
/include/net/netns/conntrack.h
每个网络命名空间有如下一个数据结构的实例,来管理和存放生成的连接的一些信息。
1 | struct netns_ct |
整体conntrack相关的数据结构如下:
conntrack的建立过程
我们先来看一下iptables定义的连接状态:
INVALID :无效连接,防火墙一般会丢弃该连接
NEW:新建立的,既只是通信双方中只一方发送了报文,还没有得到回应的
ESTABLISHED:已经得到回应的连接。既通信双方都发送过报文的连接
RELATED:关联的连接,既有期望连接关联的连接
UNTRACKED:不进行连接跟踪的连接
SNAT:配置了SNAT的连接
DNAT:配置了DNAT的连接
一般连接建立过程:
这里我们拿一个udp通信的例子来走一遍连接建立的过程。先不具体到代码的实现。
1、首先,PC和SERVER使用udp报文进行通信。
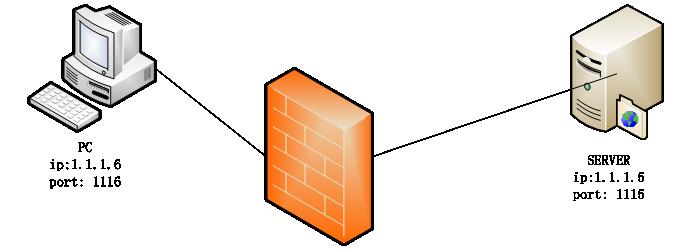
PC--------->SERVER
报文的元组信息如下:
1 | Sip:1.1.1.6 |
报文到达防火墙,防火墙的处理如下:
防火墙入口处:
- conntrack模块截获报文。
- 根据报文的元组信息在防火墙内的连接表中查找是否已经存在建立的连接,因为第一次通信,没有已建立的连接。
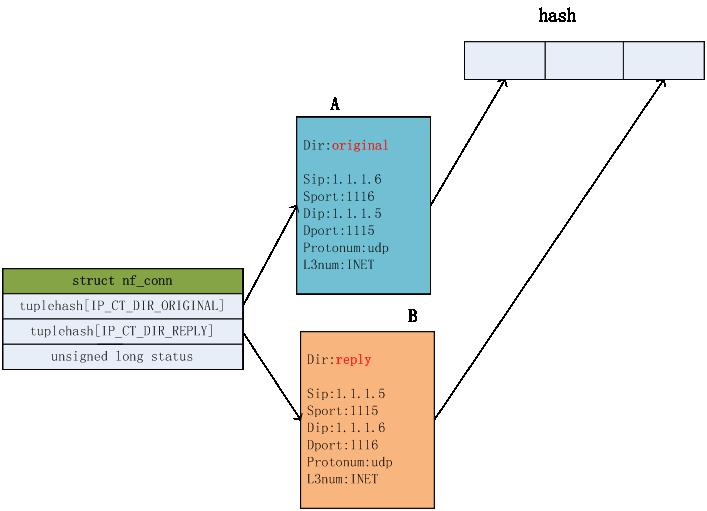
建立一个新的连接,连接的正反向元组信息如下图,并把该连接的正向连接A挂到unconfirmed链表上
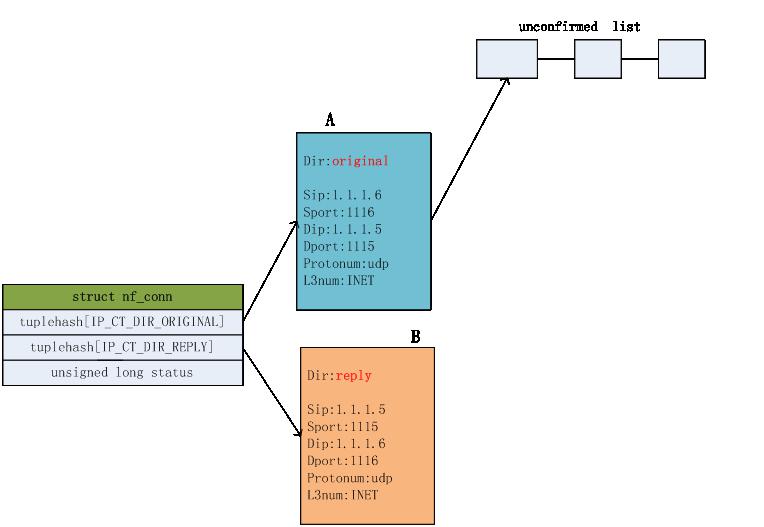
如上,新建连接后,把该连接和报文进行关联,连接状态是NEW。
防火墙出口处:
拦截报文后,根据报文携带的连接信息,找到连接,把该连接的正向连接A从unconfirmed链表上摘下来,把该连接的正反向连接A和B加入到连接hash表中。并把该连接确认状态置为confirmed状态,即置位status的IPS_CONFIRMED_BIT位。
SERVER----->PC
SERVER回应PC的报文元组信息如下:
1 | Sip:1.1.1.5 |
报文到达防火墙,防火墙的处理如下:
防火墙入口处:
- conntrack模块截获报文。
- 根据报文的元组信息在防火墙内的连接表中查找是否已经存在建立的连接,可以找到已建立的连接B。
- 发现连接B里的dir是reply,表明该连接已经有回应报文了,给连接中的status置位IPS_SEEN_REPLY_BIT,表明该连接已经收到了回应报文。这时把报文的连接状态变为ESTABLISHED
防火墙出口处:
- 拦截报文后,根据报文携带的连接信息,找到连接,发现该连接确认状态是confirmed的,直接不进行连接处理。
至此,连接建立完成。
后续该连接的正反方向的报文都可以在连接表中查到相应的连接,就可以根据连接进行相应的处理了。
期望连接的建立过程:
这里就不介绍了,详情可看原文
奉上原文后续章节:
Netfilter中conntrack 功能扩展机制
Netfilter中conntrack helper扩展实现
Netfilter中L3和L4层提供的conntrack处理方法
Netfilter中conntrack的HOOK点
Nefilter中IP conntrack核心函数详解
参考
Netfilter
netfilter/iptables 简介
Netfilter 框架及其周边组件
netfilter框架研究
使用iptables控制网络流量
深入理解Iptables和Netfilter架构
深入理解Iptables和Netfilter架构
iptables和netfilter的通信流程
netfilter内核源码分析
Netfilter内核源码分析
Netfilter全面讲解
conntrack详解